Autumn is a next-generation billing infrastructure platform for AI companies, helping them manage credit systems and AI token usage around real-time access checks and consumption, as well as making pricing models and pricing changes much more flexible. Since we’re often in the critical path of our customers’ products, we’re not just processing billing in the background, we’re helping decide in real time whether a user can make an API call, generate output, or consume more credits. That makes low latency and high uptime core product requirements for us, not just nice-to-haves.
Issues with our old database
With our previous database provider, we encountered several clear issues with relying on them as a critical piece of infrastructure. In particular, these were the largest pain-points:
- Issues with connection pooling scalability and reliability
- No zero-downtime upgrades
- Query latency was both higher than we’d like, and inconsistent over time
These issues led us to search out other solutions. PlanetScale offered what seemed like a clear solution to all of these problems. They are known for performance with PlanetScale Metal, and have a reputation for great availability and scalability.
Migration was easier than expected
Migration was much easier than we had anticipated. We were worried it’d take us weeks, but it ended up taking only 2 days.
Initially, we tried to set up the replication manually and when we faced issues, the PlanetScale support team jumped on super quick to help guide us through the entire process.
The Planetscale migration team directed us to use their custom fork of pgcopydb. This tool made the process much simpler and faster, and everything worked smoothly from here on out. Using the tool, we copied the data, ensured we were ready for a cutover, and then made the switch. All with only seconds of interim downtime.
What changed for us after switching
After migrating to PlanetScale Metal, our query latency was so low that it was honestly pretty shocking. It was nearly an order of magnitude faster than before. Previously, we were seeing our queries take ~100ms, and after moving to Planetscale it was consistently < 10ms. Not only was the latency itself much lower, but PlanetScale gives you deep visibility into query latency via Insights, both in aggregate and at the per-query level.
All the previous issues we had were addressed and more. Connection pooling is no longer a bottleneck, and we can now comfortably push for more connections as we grow. Upgrading / downgrading is really simple, with just a few clicks of a button to resize out instances.
More than just speed — the whole DX
Planetscale has been so good that we barely have to think about our DB infra anymore. Post-migration, our favourite tool has to be the Insights page. At this point, it’s already saved us from several outages. We recently had an incident where our alerts were firing for elevated response times, and we quickly noticed our DB was at 100% CPU. Using insights, we were able to determine the query causing the issue within minutes and block that particular query in our app. If we hadn’t had the level of visibility PlanetScale provides, we would’ve likely had an outage.
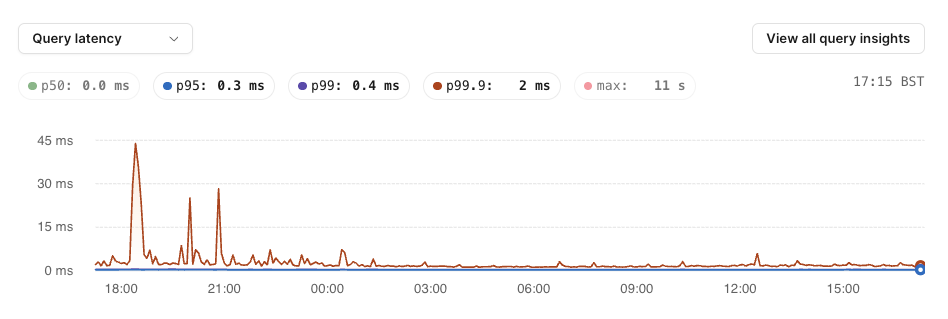
The anomalies page has also been an insane help. We recently onboarded a large customer whose huge scale revealed several holes in our schema. We were immediately able to notice this through the anomalies page showing that several queries were scanning a ton of rows and using more CPU than necessary, and we quickly added the necessary indexes to fix.
Planetscale is also very agent friendly when it comes to infra because we’ve connected our agent to Planetscale insights via the MCP server many times to debug slow queries!
The support has been unreal
Planetscale’s support team has been amazing. Response times are always quick: within hours, and sometimes even minutes. This is quite impressive, especially given we’re not on any business support tier (we’re using a self-served Planetscale Metal database).
In the past month, we’ve had especially amazing support from the team, in particular one of their Postgres engineers, Joao. When we told him we were onboarding a new large customer and were worried about DB performance, he went and debugged our queries for us. While doing so, he noticed that our most used query (which probably accounts for 80% of database requests) was not using the right indexes, and performance could be improved by about 10x.
The support here was truly unexpected as I never thought he’d actually go and debug, and furthermore help us rewrite the queries. But following his advice, we were able to reduce our CPU usage from 40% to < 10%, and the p99 for that query dropped from ~200ms to < 50ms.
The next time Joao offered insane support was when we did a table migration on a Sunday which impacted our app. Not only was it a weekend, but it was also his birthday, and he immediately jumped on for ~1 hour to help us fix the issue. Without his help that day, we would’ve probably had a catastrophic incident.
Impact on Autumn
Planetscale has been amazing for us on all fronts. Latency is better, reliability is excellent, and amazing support. We now don’t need to spend as much time debugging database issues. Can’t recommend it enough to anyone!