Last year we started to onboard companies with a global customer base. With our own users starting to appear in more regions, we decided to build a multi-region architecture to reduce latency times globally.
Initially, our services were isolated to one region, us-west.
Our aim was to reduce latency in two regions to start, us-west and us-east, and targeted a round trip latency of under 50ms. The main difficulty was that this applied to both reads and writes, so simply using DB read replicas weren’t an option. Ultimately, there were two major considerations:
- How to spin up our server in multiple regions
- More crucially though, how to make data reads and writes low latency across regions
Spinning up our server in multiple regions
There were two options here. Either we went serverless with something like Cloudflare Workers, or we manually spun up stateful servers in different regions. We went with the latter for a couple reasons:
- The whole point of this was to reduce latency. With serverless, we were afraid of inconsistent latencies due to cold startup times, which we benchmarked and proved to be true.
- Our server was already stateful, and going serverless would’ve broken patterns we relied on. Event batching, for one, gets painful when every request runs in an isolated session.
This blog from Unkey was really helpful when we made our decision. Now our next challenge was deciding on a provider. Our requirements were simple:
- Latency should be as low as possible
- Spinning up multi-region servers should be as simple as possible
Surprisingly, we tried almost every provider we could find and none of them fit perfectly. We ultimately chose AWS ECS, managed through Flightcontrol, where we spun up an ECS service in us-west and us-east, then used Route53 to route requests based on region.
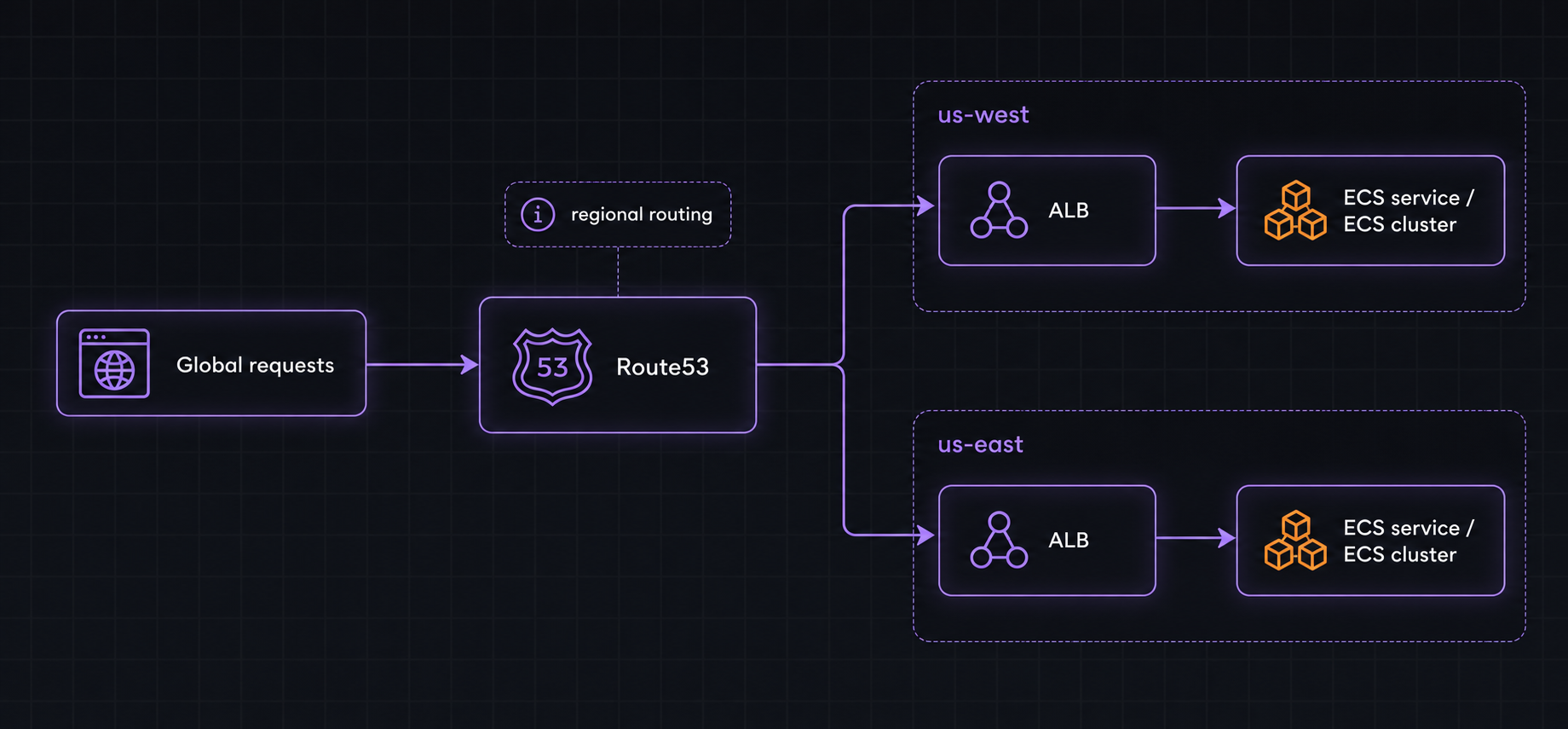
To explain why we came to this decision, it’s worth walking through the other top contenders.
We were originally on Render so this seemed like the obvious choice. However, Render doesn’t natively support multi-region, so to set this up we had to manually create instances in each region. More annoyingly though, the only way to have a single domain route to different instances was to use Cloudflare’s load balancer.
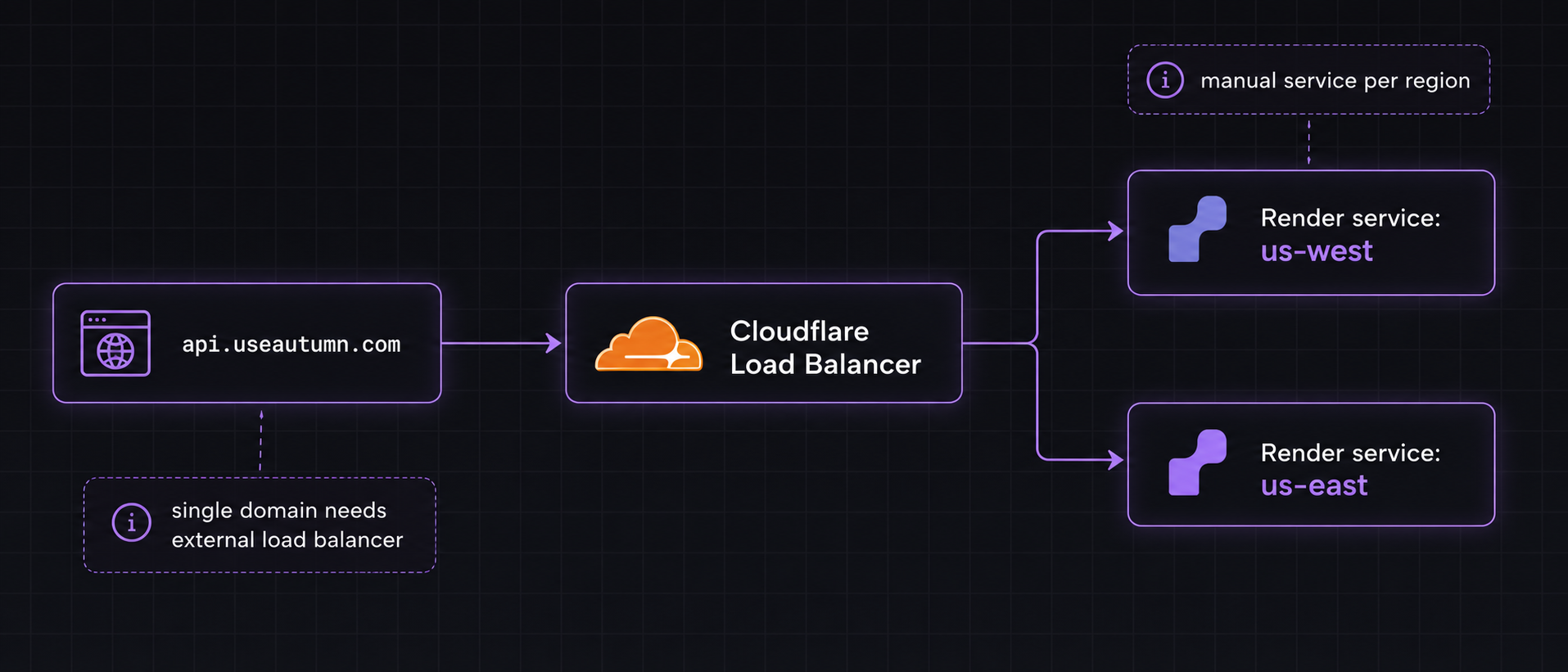
Ultimately, we chose AWS over Render because we found that Cloudflare's Load Balancer introduced additional latency compared to Route53, which resolved at the DNS layer. With Render, there were also multiple hops involved as Render itself uses Cloudflare in front of their services.
Railway was extremely compelling because they supported multi-region natively. That meant that you could spin up a single service, have it replicated across different regions, and they would handle load balancing, provisioning, and more for you. The DX was unmatched. Unfortunately though, Railway’s infra isn’t on AWS. They build their own machines. This means a couple things:
- Our database, cache, and other data stores wouldn’t be co-located with our server, unless we used Railway for those as well, which was too limiting for us
- Most of our users were also hosted on AWS so their servers wouldn’t be as close to ours
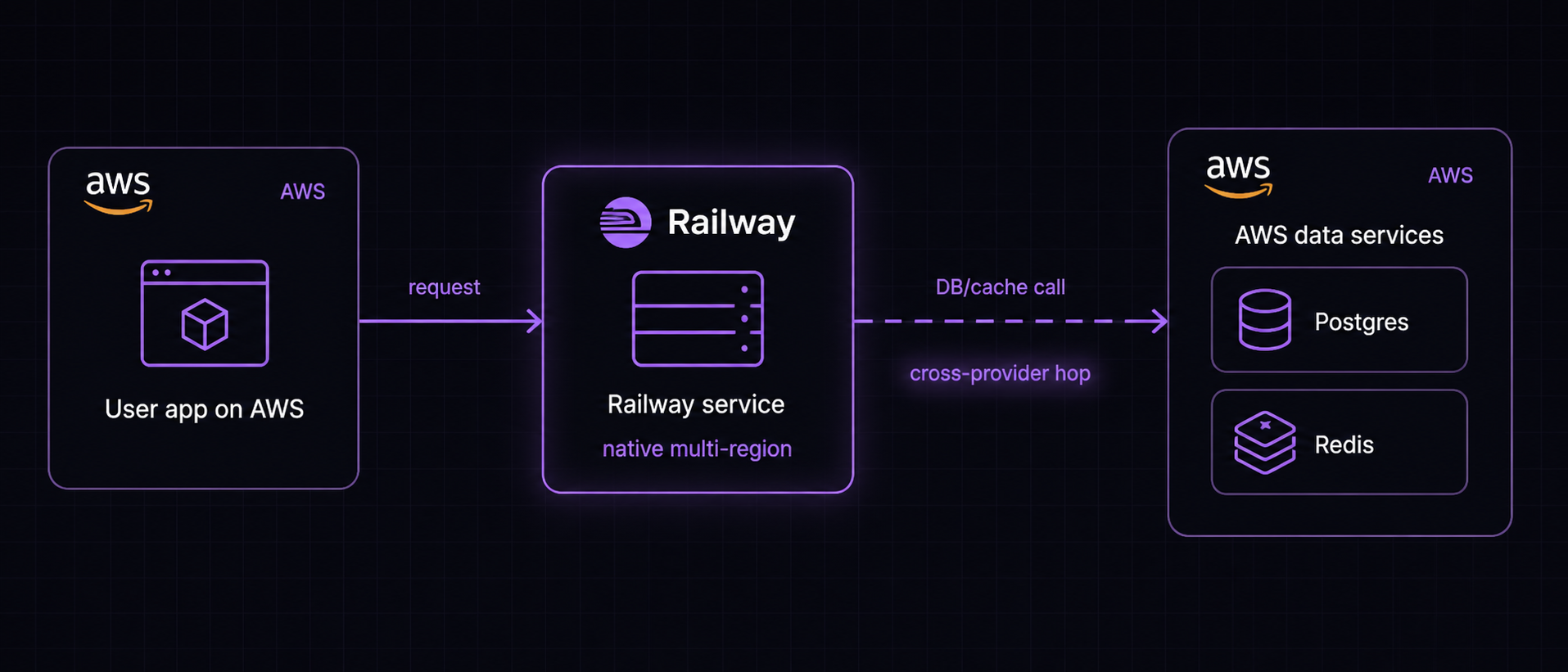
Ultimately, with both providers, the decision came down to latency. AWS consistently provided the lowest latencies in our benchmarks.

That said, ECS came with a bunch of maintenance overhead, especially coming from Render. Even with Flightcontrol, we had to build an internal dashboard to build and deploy across regions at once. Moreover, application and load balancer logs were an absolute pain to set up. But today I’m very glad we made the tradeoff. Having lower-level control over our infra has been useful, and AI has made things much easier too.
Making data reads and writes multi-region
The bigger challenge we faced was with data access: making both reads and writes fast across regions. Think of us as a complex rate limiter. Before a request is allowed through, we often need to update usage counters atomically and decide whether the customer still has access.
For example, when you send a message to Cursor, they may deduct an estimated number of credits before accepting your message, then reconcile the actual usage afterwards. Since these writes sit on the hot path, they need to be real-time and fast. We considered several approaches to solving this.
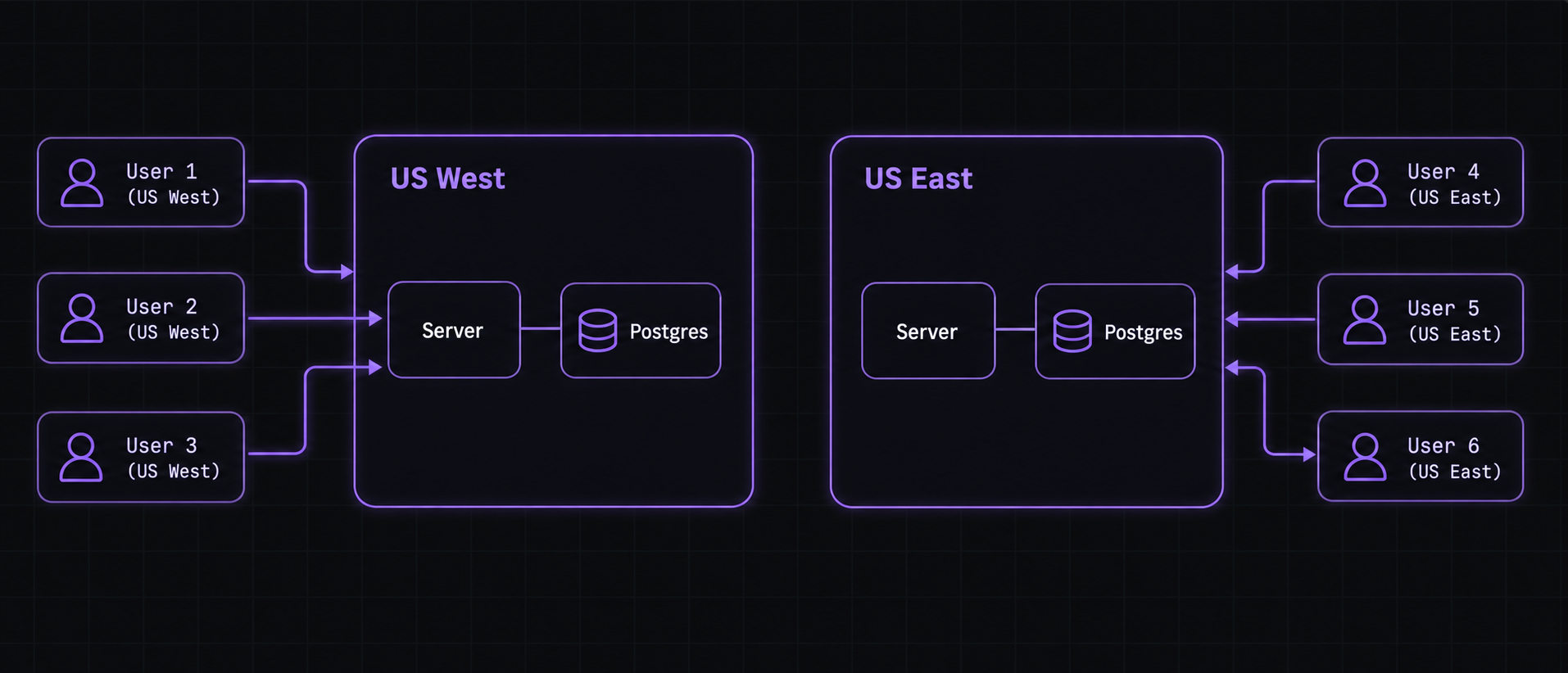
- A master database per region
We’d spin up a Postgres database in each region, completely isolated from each other, and let our users pick which region their data lives in, so it sits closest to their server. The catch, beyond running multiple databases, is that our user’s own customers might be spread across regions. For example, if they’re running Cloudflare Workers, pinning a whole account to one region doesn’t hold up.
- A region per customer
Instead of pinning our user, we could pin a customer: our user’s user. Each customer is tied to a region, and all their reads and writes happen there. We'd keep a record mapping customers to regions, and route each request accordingly.
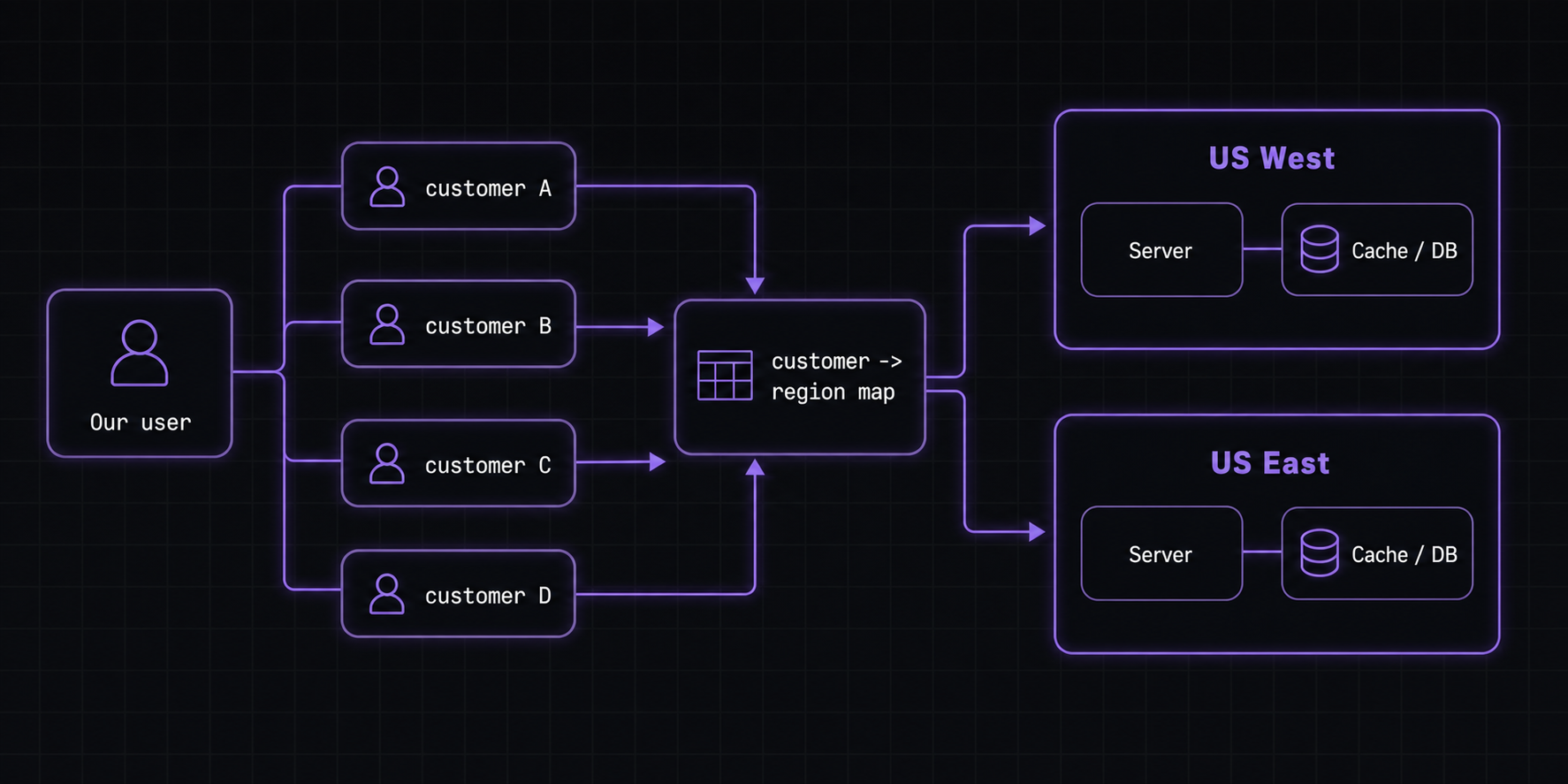
Now trying to do this with Postgres sounded like a headache. Imagine trying to JOIN data across different databases. We could simplify this with a read/write cache in each region instead of fully separate Postgres databases, but we still ruled it out because of the routing layer. We'd need yet another cache for the customer-to-region mapping, itself replicated across regions, and getting every request to the right region felt like way too much overhead.
- Active-active Redis database
The final approach, which we ended up going with, was using an Active-Active database from Redis Cloud. You spin up Redis caches in multiple regions, all fully synced, and you can write to any of them. When concurrent writes hit the same key in different regions, Redis Cloud resolves the conflict using CRDTs: Conflict-free Replicated Data Types.
Using a counter as an example: two concurrent increment operations merge into their sum rather than overwriting each other. This fit our use case perfectly. Each server connects to its own Redis cache in the cluster, and since our writes are just increments, the conflicts get resolved for us.
Why we went back
We chose the Active-Active Redis database for simplicity, and while it definitely created the least infra overhead, I think it wasn’t really the right solution for us, which led to more complexity than it was worth.
- Race conditions
First of all, with the active-active database, even though it solved that counter case perfectly, we found ourselves running into a bunch of race conditions. Take the following example:
- We store each customer as a JSON blob with
customer_idas the key - Your customer performs an upgrade on us-east so we append to their
subscriptionsarray - At the same time, Stripe sends an
invoice.paidwebhook to our us-west server and we append to the customer’sinvoicesarray
Now, both of these append operations happen on the same key and are done via a read-update-set operation. Since they happen in different regions, Redis resolves the conflict through a Last-Write-Win strategy. So either the invoices or subscriptions array will be missing an item.
To solve these types of issues, we’d often have to normalize the data. For instance, we might store the subscriptions and invoices array as separate keys, customer_id:subscriptions and customer_id:invoices. Ultimately though, we ran into these issues more often than we’d hoped, especially since it was hard to replicate a multi-region setup locally.
- Infra overhead
The second issue we kept running into was infra overhead. It wasn’t just slowing us down; it was starting to affect reliability too.
A couple of months ago, we had a user run a cron job every hour that spiked our Redis CPU and degraded the server. The quick fix would’ve been to spin up a separate Redis database for that user, so their load wouldn’t impact everyone else. But because of our multi-region architecture, what should have been a simple isolation fix became much more complex and delayed.
Reliability matters more to us than latency. So when our architecture made it harder to ship reliability fixes quickly, that was a strong signal that the tradeoff no longer made sense.
Ultimately, the thing that pushed us to move back to a single-region architecture was noticing that traffic was split roughly 95:5 between us-east and us-west. Taking on all of that complexity and giving up speed and reliability for this small slice of traffic didn’t feel worth it.
Conclusion
Ever since we’ve moved back to a single-region architecture, we’ve been way more confident in our infra and reliability, and have been able to make changes, introduce new services, and ship features way faster too. Focusing on optimizing a smaller scope has felt like a huge difference. So generally, we’re very happy about our decision. Now, two concluding thoughts:
Don’t “move fast and break things” with infra
I think the mistake we made with our multi-region setup was optimizing for simplicity and speed rather than choosing the architecture that would hold up best long term. Infra is a little counterintuitive to the usual “ship fast” startup advice. These decisions affect reliability directly, and they’re often some of the hardest decisions to reverse later. So while speed still matters, infra choices deserve more upfront thought than your average product decision.
The “smart” choice isn’t always the best one
With our original approach, I think we convinced ourselves that an Active-Active Redis database would be a silver bullet, and that choosing it was the “smart” move. But infra is all about tradeoffs. There’s a reason writable database replicas aren’t common: they add a lot of complexity, and that complexity has to show up somewhere.
We’ll definitely go back to multi-region at some point. But when we do, I think we’ll take a “less hacky” approach: route each customer to a single home region, and keep their data and traffic there. It’s much easier to reason about, and probably a lot more reliable.